
Todo lo que debes saber sobre las relaciones en base de datos: guía completa y práctica
Las relaciones en base de datos son fundamentales para organizar y estructurar la información de manera eficiente. En un mundo cada vez más digital, donde se generan grandes volúmenes de datos, es imprescindible contar con sistemas que permitan gestionarlos de forma sistemática y coherente.
Te proporcionaremos una guía completa y práctica sobre las relaciones en base de datos. Explicaremos qué son las relaciones, por qué son importantes, los diferentes tipos de relaciones que existen y cómo se implementan en el modelo entidad-relación. Además, daremos ejemplos claros y sencillos que te ayudarán a comprender mejor este concepto fundamental de la gestión de bases de datos.
- Qué son las relaciones en base de datos y por qué son importantes
- Cuáles son los tipos de relaciones más comunes en base de datos
- Cómo se establecen las relaciones entre tablas en una base de datos relacional
- Cuál es la diferencia entre una relación uno a uno, uno a muchos y muchos a muchos
- Cuándo deberías utilizar una relación uno a uno en tu base de datos
- Cuándo deberías utilizar una relación uno a muchos en tu base de datos
- Cuándo deberías utilizar una relación muchos a muchos en tu base de datos
- Qué es una clave primaria y cómo se utiliza en las relaciones de base de datos
- Cómo se representan las relaciones en un diagrama de entidad-relación
- Cuál es el papel de las llaves foráneas en las relaciones de base de datos
- Cómo se manejan los problemas de integridad referencial en las relaciones de base de datos
- Cuáles son las ventajas y desventajas de usar relaciones en base de datos
- Cómo optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones
- Cómo crear consultas JOIN para recuperar datos de tablas relacionadas
- Cuáles son las mejores prácticas para diseñar y mantener relaciones en una base de datos
- Qué implicaciones tienen las relaciones en base de datos a nivel de programación y desarrollo de aplicaciones
- ¿Qué otras consideraciones debes tener en cuenta al trabajar con relaciones en base de datos?
Qué son las relaciones en base de datos y por qué son importantes
Las relaciones en base de datos son una parte fundamental del diseño y la estructura de cualquier sistema de gestión de bases de datos (SGBD). Son utilizadas para establecer conexiones lógicas entre las tablas de una base de datos, permitiendo así organizar la información de manera eficiente y representar de manera precisa las relaciones existentes entre los diferentes conjuntos de datos.
La importancia de las relaciones en base de datos radica en que nos permiten establecer vínculos entre distintas entidades o tablas dentro de una base de datos. Esto nos permite reflejar relaciones y asociaciones entre los datos de una forma más precisa y coherente.
Además, las relaciones en base de datos facilitan el mantenimiento de la integridad referencial de los datos. Esto significa que se puede garantizar que no se puedan hacer operaciones que violen las reglas definidas en la estructura de la base de datos. Por ejemplo, si tenemos una tabla de "productos" y otra de "pedidos", podemos establecer una relación entre ellas para asegurarnos de que un producto solo pueda ser asociado a un pedido existente.
Tipos de relaciones en base de datos
Existen diferentes tipos de relaciones que se pueden establecer entre las tablas de una base de datos:
- Relación uno a uno: En este tipo de relación, cada registro en la tabla A está asociado con exactamente un registro en la tabla B, y viceversa.
- Relación uno a muchos: En este tipo de relación, cada registro en la tabla A está asociado con cero o más registros en la tabla B, pero cada registro en la tabla B solo está asociado con un único registro en la tabla A.
- Relación muchos a muchos: En este tipo de relación, cada registro en la tabla A puede estar asociado con cero o más registros en la tabla B, y cada registro en la tabla B puede estar asociado con cero o más registros en la tabla A.
Estos son solo algunos de los tipos de relaciones más comunes, pero existen otras variaciones y combinaciones posibles. La elección del tipo de relación adecuada dependerá de las necesidades específicas de cada base de datos y del diseño que se esté implementando.
Cómo establecer relaciones en base de datos
Para establecer relaciones en una base de datos, es necesario definir la clave primaria y la clave foránea en las tablas involucradas.
La clave primaria es un campo o grupo de campos que identifica de forma única cada registro en una tabla. Mientras tanto, la clave foránea es un campo en una tabla que hace referencia a la clave primaria de otra tabla.
Para establecer una relación entre dos tablas, simplemente se debe seleccionar el campo o campos de la clave primaria en la tabla principal y hacerlos coincidir con el campo o campos de la clave foránea en la tabla secundaria.
Una vez que las relaciones se han establecido correctamente, se pueden realizar operaciones de consulta y manipulación de datos que tengan en cuenta estas relaciones para obtener información precisa y coherente.
Consideraciones al utilizar relaciones en base de datos
Aunque las relaciones en base de datos tienen muchas ventajas, también es importante considerar algunas limitaciones y consideraciones:
- Las relaciones en base de datos pueden generar mayor complejidad en el diseño y mantenimiento de la base de datos. Es importante planificar y organizar cuidadosamente las relaciones para evitar posibles problemas de rendimiento o conflicto.
- Es fundamental asegurarse de que se mantenga la integridad referencial de los datos al establecer relaciones en la base de datos. Esto implica garantizar que las operaciones de inserción, actualización y eliminación cumplan con las reglas definidas en la estructura de la base de datos.
- Es necesario tener en cuenta el volumen de datos y las necesidades de rendimiento al diseñar las relaciones en una base de datos. En algunos casos, puede ser más eficiente denormalizar ciertos conjuntos de datos para evitar una excesiva complejidad en las consultas.
Tener en cuenta estas consideraciones nos ayudará a diseñar un sistema de gestión de base de datos sólido y eficiente.
Cuáles son los tipos de relaciones más comunes en base de datos
En las bases de datos, los tipos de relaciones más comunes son:
Relación uno a uno (1:1)
En este tipo de relación, un registro de una tabla se relaciona con exactamente un registro de otra tabla, y viceversa. Es decir, cada registro de una tabla está relacionado directamente con un único registro de la otra tabla.
Por ejemplo, supongamos que tenemos dos tablas: Personas y Direcciones. Cada persona puede tener solo una dirección, y cada dirección está asociada a una sola persona. Por lo tanto, habrá una relación uno a uno entre estas dos tablas.
Relación uno a muchos (1:N)
En este tipo de relación, un registro de una tabla se relaciona con uno o varios registros de otra tabla, pero los registros de la segunda tabla solo se relacionan con un único registro de la primera tabla.
Por ejemplo, consideremos las tablas Clientes y Pedidos. Un cliente puede realizar varios pedidos, pero cada pedido está asociado a un único cliente. Por lo tanto, hay una relación uno a muchos entre estas dos tablas.
Relación muchos a muchos (N:N)
En este tipo de relación, múltiples registros de una tabla pueden estar relacionados con múltiples registros de otra tabla y viceversa.
Para lograr esto, se utiliza una tabla intermedia, también conocida como tabla de unión o tabla puente. Esta tabla incluye las claves primarias de ambas tablas para establecer las relaciones entre ellas.
Por ejemplo, consideremos las tablas Estudiantes y Cursos. Un estudiante puede estar matriculado en varios cursos y, a su vez, un curso puede tener varios estudiantes. Para representar esta relación, se utilizará una tabla de unión que contenga las claves primarias de ambas tablas.
Existen otros tipos de relaciones menos comunes, como la relación recursiva (una tabla se relaciona consigo misma) y la relación polimórfica (varias tablas pueden relacionarse con una tabla en común), pero los mencionados anteriormente son los más utilizados y conocidos en las bases de datos.
Cómo se establecen las relaciones entre tablas en una base de datos relacional
En una base de datos relacional, las relaciones entre tablas se establecen a través de claves primarias y claves externas (o claves foráneas). Estas claves permiten vincular los registros de una tabla con los de otra, creando así una relación entre ellas.
La clave primaria es un campo o conjunto de campos que identifican de manera única cada registro en una tabla. Suele ser un número autoincremental o un valor único asignado por el sistema. Por ejemplo, en una tabla de usuarios, la clave primaria puede ser el campo "ID_usuario".
Por otro lado, la clave externa es un campo en una tabla que hace referencia a la clave primaria de otra tabla. Esto crea una relación entre las dos tablas, donde el campo con la clave externa actúa como un enlace hacia la tabla referenciada. Por ejemplo, si tenemos una tabla de pedidos y otra de clientes, podemos utilizar la clave externa "ID_cliente" en la tabla de pedidos para relacionar cada pedido con el cliente correspondiente.
Ejemplo de cómo se establece una relación entre tablas
Supongamos que tenemos dos tablas: "clientes" y "pedidos". La tabla "clientes" tiene los siguientes campos:
ID_cliente: clave primarianombreemail
La tabla "pedidos" tiene los siguientes campos:
ID_pedido: clave primariaID_cliente: clave externaproductocantidadprecio
En este caso, la clave externa ID_cliente en la tabla "pedidos" hace referencia a la clave primaria ID_cliente en la tabla "clientes". Esto permite establecer una relación entre los pedidos y los clientes, de manera que cada pedido esté asociado a un cliente específico.
Tipo de relaciones en base de datos
Existen diferentes tipos de relaciones que se pueden establecer entre tablas en una base de datos relacional:
- Relación uno a uno: cada registro de una tabla está relacionado con exactamente un registro de otra tabla. Por ejemplo, si tenemos una tabla de empleados y otra de direcciones, cada empleado puede tener una sola dirección y cada dirección está asociada a un solo empleado.
- Relación uno a muchos: cada registro de una tabla está relacionado con varios registros de otra tabla. Por ejemplo, si tenemos una tabla de departamentos y otra de empleados, cada departamento puede tener varios empleados pero cada empleado solo pertenece a un departamento.
- Relación muchos a muchos: varios registros de una tabla están relacionados con varios registros de otra tabla. Para modelar esta relación se requiere de una tabla intermedia (también conocida como tabla de unión o tabla puente) que contiene las claves primarias de ambas tablas. Por ejemplo, si tenemos una tabla de estudiantes y otra de cursos, la tabla intermedia podría ser "matrículas", donde se registrarían las asignaciones de estudiantes a cursos.
Estas son solo algunas de las posibles formas de establecer relaciones entre tablas en una base de datos relacional. La elección del tipo de relación dependerá de la estructura y los requerimientos específicos de cada sistema.
Cuál es la diferencia entre una relación uno a uno, uno a muchos y muchos a muchos
Una de las primeras cosas que debes entender cuando trabajas con bases de datos es el concepto de relaciones. Las relaciones son vínculos entre diferentes tablas en una base de datos. Hay tres tipos principales de relaciones: uno a uno, uno a muchos y muchos a muchos.
Relación uno a uno
En una relación uno a uno, un registro en una tabla está relacionado con exactamente un registro en otra tabla, y viceversa. Esto significa que la relación es única y recíproca. Un ejemplo común de una relación uno a uno es una tabla de "empleados" y una tabla de "datos personales". Cada empleado tiene una sola entrada en la tabla de datos personales y viceversa.
Relación uno a muchos
En una relación uno a muchos, un registro en una tabla se relaciona con varios registros en otra tabla, pero los registros en la segunda tabla solo están relacionados con un único registro en la primera tabla. Esta es la relación más común en las bases de datos y se utiliza para representar conexiones como "un autor tiene muchos libros".
Relación muchos a muchos
En una relación muchos a muchos, múltiples registros en una tabla pueden estar relacionados con múltiples registros en otra tabla. Para representar esta relación, se utiliza una tabla intermedia que contiene las claves primarias de ambas tablas para establecer la conexión. Por ejemplo, en una base de datos de una tienda en línea, puede haber una tabla de "productos" y una tabla de "categorias". Varios productos pueden pertenecer a varias categorías y viceversa.
Cuándo deberías utilizar una relación uno a uno en tu base de datos
Una relación uno a uno en una base de datos se utiliza cuando necesitas relacionar dos entidades o tablas de manera que cada registro de una tabla esté relacionado con exactamente un registro de la otra tabla. Esto se logra mediante el uso de claves primarias y claves foráneas.
Existen varias situaciones en las cuales puede ser adecuado utilizar una relación uno a uno en tu base de datos:
- Cuando tienes información adicional sobre un registro que no quieres almacenar en la misma tabla para mantenerla ordenada y evitar la duplicación de datos. Por ejemplo, si tienes una tabla de "Usuarios" y quieres almacenar información de contacto como dirección, teléfono, etc., podrías crear una tabla separada de "Contacto" con una relación uno a uno donde cada registro de "Usuario" tenga una única asociación con "Contacto". Esto te permitirá tener información más organizada y evitará tener campos vacíos en la tabla principal.
- Cuando quieres separar información sensible o confidencial. En algunos casos, puedes tener información en tu base de datos que sea considerada más sensible o privada que el resto de los datos. Al separar esta información en una tabla adicional y establecer una relación uno a uno, puedes aplicar medidas de seguridad adicionales a esta tabla específica, como cifrado o restricciones de acceso más estrictas.
- Cuando la información adicional puede no estar siempre presente. Hay ocasiones en las que cierta información es opcional o simplemente puede no estar disponible para todos los registros. En lugar de dejar campos vacíos en la tabla principal, puedes almacenar esta información en una tabla secundaria y establecer una relación uno a uno. De esta manera, solo los registros que tienen información adicional estarán asociados con la tabla secundaria, lo que te permite ahorrar espacio y mejorar el rendimiento de las consultas.
- Cuando necesitas dividir una entidad en subentidades más especializadas. En algunos casos, una entidad puede tener atributos o características adicionales que solo son relevantes para un subconjunto específico de registros. Al crear una relación uno a uno entre la entidad principal y una tabla secundaria, puedes almacenar estos atributos adicionales solo para los registros correspondientes y mantener la integridad y coherencia de tus datos.
En definitiva, utilizar una relación uno a uno en tu base de datos puede ser beneficioso para organizar y mantener la integridad de tus datos, salvaguardar información sensible y optimizar el rendimiento de las consultas. Sin embargo, debes evaluar cuidadosamente cada caso y considerar si realmente es necesario antes de implementarla en tu diseño de base de datos.
Cuándo deberías utilizar una relación uno a muchos en tu base de datos
Una relación uno a muchos en una base de datos se utiliza cuando tienes una entidad principal que está relacionada con múltiples entidades secundarias. Esta relación es comúnmente representada por una llave externa en la tabla secundaria que refiere a la llave primaria de la tabla principal. En otras palabras, para cada registro en la tabla principal, puede haber varios registros asociados en la tabla secundaria.
Existen varias situaciones en las que es recomendable utilizar una relación uno a muchos en tu base de datos. Algunos ejemplos son:
- Relación entre usuarios y publicaciones: Imagina que estás desarrollando una aplicación de blog donde los usuarios pueden crear publicaciones. Cada usuario puede tener múltiples publicaciones asociadas a su cuenta. En este caso, sería apropiado utilizar una relación uno a muchos entre la tabla de usuarios y la tabla de publicaciones. La llave primaria en la tabla de usuarios se convertiría en la llave externa en la tabla de publicaciones.
- Relación entre un cliente y sus pedidos: Si estás creando un sistema de comercio electrónico, es probable que tengas una tabla de clientes y una tabla de pedidos. Cada cliente puede realizar múltiples pedidos, por lo que una relación uno a muchos sería adecuada en este caso. La llave primaria en la tabla de clientes se utilizaría como llave externa en la tabla de pedidos.
- Relación entre una categoría y sus productos: Supongamos que estás construyendo una tienda en línea donde tienes diferentes categorías de productos y cada categoría contiene varios productos. En este caso, una relación uno a muchos entre la tabla de categorías y la tabla de productos sería la opción correcta. La llave primaria en la tabla de categorías se convertiría en la llave externa en la tabla de productos.
Es importante tener en cuenta que una relación uno a muchos es solo uno de los tipos de relaciones disponibles en bases de datos. Dependiendo de tu aplicación y requerimientos, podrías necesitar utilizar otros tipos de relaciones como las relaciones muchos a muchos o las relaciones uno a uno.
Utilizar una relación uno a muchos en tu base de datos es apropiado cuando necesitas relacionar una entidad principal con múltiples entidades secundarias. Esta relación puede ser útil en escenarios como usuarios y publicaciones, clientes y pedidos, o categorías y productos.
Cuándo deberías utilizar una relación muchos a muchos en tu base de datos
Una relación muchos a muchos se utiliza cuando deseas representar una asociación entre dos entidades en tu base de datos donde ambas entidades pueden tener múltiples instancias relacionadas entre sí. Este tipo de relación es especialmente útil cuando existe una correspondencia de muchos a muchos en la vida real.
Para entenderlo mejor, considera el ejemplo de una aplicación de gestión de proyectos. En este caso, puedes tener una entidad de "Proyecto" y otra entidad de "Empleado". Cada proyecto puede estar asignado a varios empleados y cada empleado puede trabajar en varios proyectos diferentes. Aquí es donde una relación muchos a muchos sería apropiada.
En términos de diseño de base de datos, una relación muchos a muchos generalmente se implementa mediante el uso de una tabla de relación intermedia. Esta tabla actúa como un enlace entre las dos entidades principales y contiene las claves primarias de ambos lados de la relación.
Por ejemplo, en el caso del ejemplo de la gestión de proyectos, podríamos tener una tabla llamada "Asignaciones" con columnas como "ID del Proyecto", "ID del Empleado" y cualquier otra información relevante sobre la asignación en particular.
Al utilizar una relación muchos a muchos, puedes representar eficientemente esta asociación compleja en tu base de datos sin redundancia ni inconsistencias en los datos.
Qué es una clave primaria y cómo se utiliza en las relaciones de base de datos
Una clave primaria en una base de datos es un campo o conjunto de campos que identifica de manera única cada registro en una tabla. Se utiliza para garantizar la integridad y consistencia de los datos, ya que no puede haber duplicados en la clave primaria. La clave primaria se define al crear la tabla y suele ser autoincremental, lo que significa que se genera automáticamente un valor único para cada nuevo registro insertado.
Para utilizar una clave primaria en las relaciones de base de datos, se debe establecer una relación entre tablas utilizando esta clave. En la tabla principal, se define la clave primaria como un campo y en la tabla secundaria, se define la clave primaria como una clave externa o clave foránea.
Ejemplo práctico de uso de clave primaria en una relación de base de datos
Supongamos que tenemos dos tablas en una base de datos: "Clientes" y "Pedidos". La tabla "Clientes" tiene una clave primaria llamada "id_cliente", que es un número único para cada cliente. La tabla "Pedidos" tiene una clave primaria llamada "id_pedido" y también tiene un campo llamado "cliente_id" que hace referencia a la clave primaria de la tabla "Clientes". De esta manera, se establece una relación entre las tablas.
CREATE TABLE Clientes (
id_cliente INT PRIMARY KEY AUTO_INCREMENT,
nombre VARCHAR(50),
telefono VARCHAR(15)
);
CREATE TABLE Pedidos (
id_pedido INT PRIMARY KEY AUTO_INCREMENT,
cliente_id INT,
fecha_pedido DATE
);
ALTER TABLE Pedidos ADD FOREIGN KEY (cliente_id) REFERENCES Clientes(id_cliente);
En el ejemplo anterior, se crea la tabla "Clientes" con una clave primaria de tipo entero autoincremental. Luego, se crea la tabla "Pedidos" con una clave primaria de tipo entero autoincremental y un campo "cliente_id" que hace referencia a la clave primaria de la tabla "Clientes". Por último, se agrega una restricción de clave foránea para garantizar la integridad referencial entre las tablas.
De esta manera, cada vez que se inserta un nuevo pedido en la tabla "Pedidos", se debe especificar el ID del cliente al que pertenece ese pedido. Esto permite establecer una relación entre los clientes y sus pedidos, y realizar consultas que involucren datos de ambas tablas.
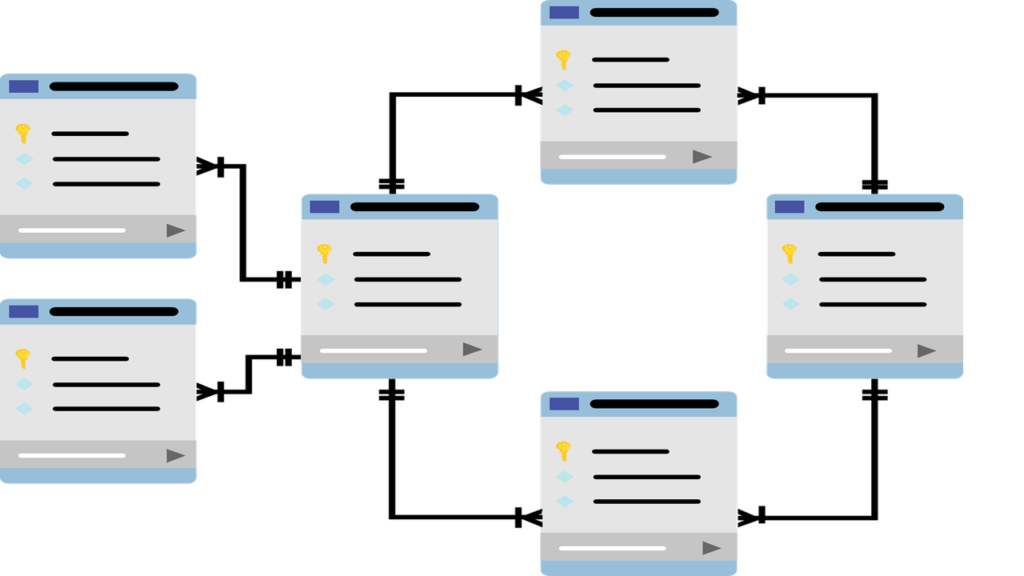
Cómo se representan las relaciones en un diagrama de entidad-relación
En un diagrama de entidad-relación, las relaciones se representan mediante líneas que conectan las entidades involucradas. Estas líneas indican la existencia de una relación entre las entidades y pueden tener diferentes características según el tipo de relación.
Tipo de relaciones
Existen varios tipos de relaciones que se pueden representar en un diagrama de entidad-relación:
- Relación uno a uno (1:1): Este tipo de relación indica que una entidad está asociada con otra entidad de forma exclusiva. Se representa con una línea recta que une las dos entidades.
- Relación uno a muchos (1:N): En este caso, una entidad puede estar asociada con múltiples instancias de otra entidad. Se representa con una línea de rombo entre las dos entidades, donde el rombo apunta hacia la entidad "uno" y la línea se dirige hacia la entidad "muchos".
- Relación muchos a uno (N:1): Es similar a la relación uno a muchos, pero en orden inverso. Esto significa que varias instancias de una entidad se vinculan con una sola instancia de otra entidad. La representación es la misma que en la relación uno a muchos.
- Relación muchos a muchos (N:N): En este caso, múltiples instancias de una entidad pueden estar asociadas con múltiples instancias de otra entidad. Se representa con un rombo que apunta hacia ambas entidades y una línea que conecta los rombos.
Atributos de las relaciones
Además de representar el tipo de relación, también se pueden agregar atributos a las relaciones en un diagrama de entidad-relación. Estos atributos son propiedades o características específicas de la relación que pueden brindar más información sobre cómo se relacionan las entidades.
Por ejemplo, si estamos modelando una relación entre las entidades "Cliente" y "Pedido", podríamos agregar el atributo "fecha" a la relación para indicar cuándo se realizó el pedido. Otros ejemplos de atributos podrían ser "cantidad" para indicar la cantidad de productos solicitados en el pedido o "estado" para indicar si el pedido está pendiente, en proceso o completado.
Cardinalidad de las relaciones
La cardinalidad de una relación indica cuántas instancias de una entidad están involucradas en la relación con respecto a las instancias de la otra entidad.
Cuál es el papel de las llaves foráneas en las relaciones de base de datos
Las llaves foráneas son un componente fundamental en las relaciones de base de datos. Son utilizadas para establecer y mantener la integridad referencial entre dos tablas. En términos simples, una llave foránea es una columna o conjunto de columnas en una tabla que hace referencia a la clave primaria de otra tabla.
Al utilizar llaves foráneas, se pueden establecer relaciones entre diferentes tablas en una base de datos, lo que permite almacenar y vincular información de manera eficiente y precisa. Estas relaciones se basan en la idea de que una llave foránea (o conjunto de ellas) en una tabla apunta a la clave primaria de otra tabla, lo que implica una conexión lógica entre los datos de ambas tablas.
Cómo se definen las llaves foráneas
Para definir una llave foránea en una tabla, se utiliza la cláusula FOREIGN KEY seguida del nombre de la columna (o conjunto de columnas) que actuará como llave foránea y la cláusula REFERENCES con el nombre de la tabla y columna(s) de la clave primaria a la que se está haciendo referencia. Por ejemplo:
CREATE TABLE tabla1 (
id_tabla1 INT PRIMARY KEY,
columna1 VARCHAR(50),
id_tabla2 INT FOREIGN KEY REFERENCES tabla2(id_tabla2)
);
En este ejemplo, la tabla "tabla1" tiene una llave primaria llamada "id_tabla1" y una llave foránea llamada "id_tabla2" que hace referencia a la tabla "tabla2" y su clave primaria "id_tabla2". Esto establece una relación entre las dos tablas.
Tipos de restricciones en llaves foráneas
Las llaves foráneas pueden tener diferentes tipos de restricciones, que ayudan a garantizar la integridad referencial y evitar inconsistencias en los datos. Algunas de las restricciones comunes son:
- ON DELETE CASCADE: Si se elimina una fila en la tabla referenciada, todas las filas relacionadas en la tabla que contiene la llave foránea también se eliminan automáticamente.
- ON UPDATE CASCADE: Si se actualiza el valor de una fila en la columna referenciada, todas las filas relacionadas en la tabla que contiene la llave foránea se actualizan automáticamente.
- ON DELETE SET NULL: Si se elimina una fila en la tabla referenciada, el valor de la llave foránea en la tabla que la contiene se establecerá como NULL.
- ON UPDATE SET NULL: Si se actualiza el valor de una fila en la columna referenciada, el valor de la llave foránea en la tabla que la contiene se establecerá como NULL.
- ON DELETE RESTRICT: No se permite eliminar una fila en la tabla referenciada si hay filas relacionadas en la tabla que contiene la llave foránea.
- ON UPDATE RESTRICT: No se permite actualizar el valor de una fila en la columna referenciada si hay filas relacionadas en la tabla que contiene la llave foránea.
Estas restricciones se definen al momento de crear la llave foránea y ayudan a mantener la integridad de los datos en las relaciones de base de datos.
Cómo se manejan los problemas de integridad referencial en las relaciones de base de datos
Los problemas de integridad referencial son situaciones en las que los datos almacenados en una base de datos relacionales no cumplen con ciertas restricciones o reglas definidas en la estructura de las relaciones. Estos problemas pueden ocurrir cuando se intenta insertar, actualizar o eliminar datos en una tabla relacionada sin respetar las dependencias establecidas.
Existen diferentes formas de manejar los problemas de integridad referencial en las relaciones de base de datos. A continuación, se presentan algunas técnicas y prácticas comunes utilizadas para garantizar que la integridad de los datos sea mantenida correctamente:
1. Restricciones de clave primaria y clave foránea
Las restricciones de clave primaria y clave foránea son uno de los métodos más comunes para mantener la integridad referencial en una base de datos. La clave primaria es un campo o combinación de campos que identifica de forma única cada registro en una tabla. La clave foránea, por otro lado, es un campo o combinación de campos que hace referencia a una clave primaria en otra tabla. Al establecer estas restricciones, se asegura que solo se puedan insertar o actualizar registros si se cumple con las dependencias establecidas.
CREATE TABLE usuarios (
id INT PRIMARY KEY,
nombre VARCHAR(50)
);
CREATE TABLE compras (
id INT PRIMARY KEY,
usuario_id INT,
producto VARCHAR(50),
FOREIGN KEY (usuario_id) REFERENCES usuarios(id)
);
En el ejemplo anterior, la tabla "compras" tiene una clave foránea ("usuario_id") que hace referencia a la clave primaria ("id") de la tabla "usuarios". Esto garantiza que solo se puedan ingresar registros en la tabla "compras" si existe un registro correspondiente en la tabla "usuarios".
2. Reglas de cascada
Las reglas de cascada son utilizadas cuando se desea definir el efecto que debe tener una operación (como una inserción o eliminación) en las tablas relacionadas. Las opciones más comunes son:
- CASCADE: cuando se realiza una operación, se propagan los cambios a las tablas relacionadas.
- RESTRICT: se impide la realización de una operación si viola la integridad referencial.
- SET NULL: se establece el valor de la clave foránea en NULL si el registro relacionado es eliminado.
- SET DEFAULT: se establece el valor de la clave foránea en su valor predeterminado si el registro relacionado es eliminado.
Estas reglas ayudan a mantener la coherencia y consistencia de los datos en las relaciones.
3. Transacciones y bloqueo de datos
Otra forma de manejar la integridad referencial en las relaciones de base de datos es utilizando transacciones y bloqueo de datos. Una transacción es una secuencia de operaciones que se ejecutan como una sola unidad lógica de trabajo. En este contexto, las operaciones pueden incluir inserciones, actualizaciones o eliminaciones de datos en las tablas relacionadas.
El bloqueo de datos, por otro lado, es una técnica utilizada para evitar que múltiples usuarios realicen cambios simultáneos en los mismos datos. Cuando se realiza una transacción en una base de datos, se pueden aplicar bloqueos para garantizar que otros usuarios no puedan modificar los datos relacionados hasta que la transacción se complete correctamente.
El uso adecuado de las transacciones y el bloqueo de datos puede ayudar a evitar problemas de integridad referencial al asegurar que las operaciones se realicen de manera secuencial y controlada.
Cuáles son las ventajas y desventajas de usar relaciones en base de datos
Las relaciones en base de datos permiten establecer conexiones entre diferentes tablas, lo que agrega flexibilidad y eficiencia al manejar grandes cantidades de datos. Aunque las relaciones pueden ser beneficiosas, también tienen algunas desventajas a considerar.
Ventajas de usar relaciones en base de datos:
- Eliminación de la redundancia de datos: Al utilizar relaciones, se evita la duplicación innecesaria de información en múltiples lugares, lo que ayuda a mantener una base de datos más consistente y fácil de mantener. Esto es especialmente útil cuando se necesita actualizar o modificar el dato relacionado en varios lugares.
- Integridad referencial: Las relaciones en base de datos permiten establecer restricciones y reglas que aseguran que los datos relacionados sean consistentes y correctos. Por ejemplo, se puede definir que un registro en una tabla (tabla secundaria) solo puede existir si existe otro registro en otra tabla (tabla principal).
- Escalabilidad: Las relaciones permiten ampliar la base de datos y agregar nuevas tablas sin afectar directamente las ya existentes. Esto facilita la gestión del crecimiento de la base de datos a medida que se agregan nuevos registros y se realizan cambios en la estructura.
- Análisis de datos complejos: Al utilizar relaciones, es posible realizar consultas y análisis de datos complejos mediante el uso de JOINs y otras operaciones relacionales. Esto es especialmente útil cuando se requiere extraer información de múltiples tablas de forma eficiente.
Desventajas de usar relaciones en base de datos:
- Complejidad: Utilizar relaciones en base de datos agrega un nivel adicional de complejidad tanto en el diseño como en la consulta de los datos. Es necesario comprender y aplicar correctamente las claves primarias, foráneas y las reglas de integridad referencial.
- Mayor tiempo de ejecución: Las consultas que involucran varias tablas pueden requerir más tiempo para ejecutarse que aquellas que solo manipulan una tabla. Esto se debe a la necesidad de unir o combinar la información de múltiples tablas.
- Posible pérdida de rendimiento: Una mala administración de las relaciones puede llevar a una disminución en el rendimiento de la base de datos. Por ejemplo, si hay una alta cantidad de JOINs innecesarios o mal diseñados, esto puede causar cuellos de botella y ralentizar la consulta de datos.
- Mayor complejidad en la migración y actualización: Cuando se realizan cambios en la estructura o esquema de la base de datos, como agregar o eliminar tablas o modificar relaciones existentes, puede ser complicado realizar la migración y actualización sin afectar la integridad de los datos existentes.
A pesar de estas desventajas, en la mayoría de los casos, las ventajas de utilizar relaciones en una base de datos superan con creces las desventajas. Sin embargo, es importante evaluar cuidadosamente las necesidades y requerimientos específicos del proyecto antes de decidir si utilizar o no relaciones en base de datos.
Cómo optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones
Cuando trabajamos con bases de datos relacionales, una de las preocupaciones más comunes es el rendimiento de las consultas. Las relaciones entre tablas pueden afectar significativamente la velocidad de ejecución de las consultas y, por lo tanto, es importante optimizarlas adecuadamente.
Existen varias técnicas que podemos utilizar para mejorar el rendimiento de las consultas en bases de datos relacionales con relaciones. A continuación, se presentan algunas de las mejores prácticas a tener en cuenta:
1. Utilizar índices adecuados
Un índice es una estructura de datos que mejora la velocidad de recuperación de registros en una tabla. Al crear índices en las columnas que se utilizan frecuentemente en las consultas, se puede reducir el tiempo de búsqueda y mejorar el rendimiento general del sistema.
Es importante analizar detenidamente las consultas más comunes y determinar qué columnas son utilizadas con mayor frecuencia. Estas columnas deben ser candidatas a tener índices. Sin embargo, es necesario tener en cuenta que los índices también ocupan espacio en disco, por lo que es importante equilibrar la cantidad de índices creados con el impacto en el rendimiento y almacenamiento.
2. Utilizar claves primarias y foráneas correctamente
Las claves primarias y foráneas son elementos fundamentales en la creación de relaciones entre tablas. Una clave primaria es única en una tabla y se utiliza para identificar de manera única cada registro. Las claves foráneas se utilizan para establecer relaciones entre tablas.
Al utilizar claves primarias y foráneas correctamente, se pueden optimizar las operaciones de inserción, actualización y eliminación en las tablas relacionadas. Esto se debe a que las claves primarias y foráneas permiten que la base de datos realice comprobaciones de integridad referencial de manera eficiente.
3. Evitar consultas innecesarias
Es importante evitar realizar consultas innecesarias, ya que esto puede afectar negativamente el rendimiento del sistema. Para lograr esto, es recomendable analizar y optimizar las consultas existentes antes de ejecutarlas en producción.
Una forma de evitar consultas innecesarias es utilizando técnicas de optimización de consultas, como el uso de índices adecuados, la normalización de la estructura de la base de datos y la utilización de claves foráneas correctamente.
4. Utilizar joins eficientes
Los joins se utilizan para combinar registros de dos o más tablas basándose en una columna común. Sin embargo, dependiendo de cómo se utilicen los joins, pueden generar consultas lentas y pesadas.
Para asegurar un rendimiento óptimo, es importante utilizar los joins de manera eficiente. Esto implica seleccionar el tipo de join adecuado (inner join, left join, right join, etc.) y definir correctamente las condiciones de unión.
SELECT *
FROM tabla1
JOIN tabla2 ON tabla1.columna = tabla2.columna
WHERE condicion
En el ejemplo anterior, "tabla1" y "tabla2" son las tablas que queremos combinar y "columna" es la columna común utilizada para unir las tablas. La "condicion" es opcional y puede filtrar los registros que queremos obtener.
5. Utilizar vistas materializadas
Una vista materializada es una tabla precalculada que almacena el resultado de una consulta compleja. Usar vistas materializadas puede mejorar significativamente el rendimiento de las consultas, especialmente cuando la consulta es costosa en términos de tiempo de ejecución.
Al utilizar vistas materializadas, se reduce el tiempo necesario para ejecutar una consulta compleja porque los resultados ya están almacenados en una tabla. Sin embargo, es importante tener en cuenta que las vistas materializadas ocupan espacio en disco y deben ser actualizadas periódicamente para mantener la información actualizada.
- Optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones requiere tomar en consideración varios aspectos importantes:
- Utilizar índices adecuados para acelerar las búsquedas
- Utilizar claves primarias y foráneas correctamente para optimizar operaciones de inserción, actualización y eliminación/li>
- Avoid consultar innecesariamente
- Utilizar joins eficientes para combinar registros de manera óptima
- Utilizar vistas materializadas para aprovechar resultados precalculados
Cómo crear consultas JOIN para recuperar datos de tablas relacionadas
Una de las características más importantes de las bases de datos relacionales es la capacidad de crear relaciones entre tablas y recuperar datos combinados utilizando consultas JOIN. Esto permite que los datos se extraigan de múltiples tablas y se combinen en una sola vista, lo que facilita el análisis y la visualización de la información.
Existen diferentes tipos de JOIN que se pueden utilizar para combinar datos de múltiples tablas:
INNER JOIN
El INNER JOIN devuelve solo los registros que tienen coincidencias en ambas tablas. Solo se devuelven los registros donde la clave de la primera tabla coincide con la clave de la segunda tabla definida en la cláusula ON.
SELECT columna1, columna2, ...
FROM tabla1
INNER JOIN tabla2
ON tabla1.columna = tabla2.columna;
LEFT JOIN
El LEFT JOIN devuelve todos los registros de la tabla izquierda (tabla1) y los registros coincidentes de la tabla derecha (tabla2). Si no hay coincidencias, se devuelven valores NULL para las columnas de la tabla derecha.
SELECT columna1, columna2, ...
FROM tabla1
LEFT JOIN tabla2
ON tabla1.columna = tabla2.columna;
RIGHT JOIN
El RIGHT JOIN devuelve todos los registros de la tabla derecha (tabla2) y los registros coincidentes de la tabla izquierda (tabla1). Si no hay coincidencias, se devuelven valores NULL para las columnas de la tabla izquierda.
SELECT columna1, columna2, ...
FROM tabla1
RIGHT JOIN tabla2
ON tabla1.columna = tabla2.columna;
FULL JOIN
El FULL JOIN devuelve todos los registros de ambas tablas, incluidos los registros que no tienen coincidencias en la otra tabla. Si no hay coincidencias, se devuelven valores NULL para las columnas sin correspondencia.
SELECT columna1, columna2, ...
FROM tabla1
FULL JOIN tabla2
ON tabla1.columna = tabla2.columna;
Además, es importante tener en cuenta que también se pueden usar combinaciones múltiples de JOIN en una sola consulta. Esto permite combinar más de dos tablas y recuperar datos de acuerdo a las condiciones definidas en la cláusula ON.
Las consultas JOIN son una herramienta poderosa para recuperar datos de tablas relacionadas. Proporcionan flexibilidad y eficiencia al permitirnos combinar información de forma sencilla y obtener resultados precisos para nuestros análisis.
Cuáles son las mejores prácticas para diseñar y mantener relaciones en una base de datos
Cuando se trata de diseñar y mantener relaciones en una base de datos, es importante seguir las mejores prácticas para garantizar un rendimiento óptimo y evitar problemas futuros. En esta guía completa y práctica, te mostraremos algunas recomendaciones clave para diseñar y mantener relaciones en tu base de datos.
1. Normalización de la base de datos
Una de las mejores prácticas para el diseño de relaciones en una base de datos es seguir los principios de normalización. La normalización ayuda a evitar la redundancia de datos y mejora la integridad de la base de datos. Hay diferentes formas normales que debes seguir, desde la primera forma normal (1NF) hasta la tercera forma normal (3NF) y más allá si es necesario. Al seguir estas formas normales, podrás reducir la duplicación de datos y hacer que tus relaciones sean más eficientes.
2. Definición adecuada de las claves primarias y foráneas
Otra práctica importante es asegurarse de definir correctamente las claves primarias y foráneas en tus tablas. Las claves primarias son únicas y se utilizan para identificar de manera única cada registro en una tabla. Por otro lado, las claves foráneas se utilizan para establecer relaciones entre tablas y asegurarse de que los datos estén correctamente vinculados.
Es crucial que las claves primarias sean únicas y no nulas, mientras que las claves foráneas deben estar correctamente definidas para asegurar la integridad referencial de los datos. Además, es importante establecer índices en estas claves para mejorar el rendimiento de las consultas.
3. Uso adecuado de los tipos de datos
Seleccionar los tipos de datos adecuados para tus columnas es otro aspecto crítico del diseño de relaciones en una base de datos. Utilizar los tipos de datos correctos no solo ahorra espacio y mejora el rendimiento, sino que también asegura la validez y consistencia de los datos almacenados.
Es importante utilizar tipos de datos apropiados para cada columna en función de su propósito y contenido. Por ejemplo, utilizar el tipo de datos adecuado para almacenar fechas y horas, así como utilizar tipos numéricos precisos para valores numéricos. Esto ayudará a evitar problemas de almacenamiento y agilizará las operaciones de consulta.
4. Establecimiento de restricciones y reglas de integridad
NOT NULL: Esta restricción garantiza que un campo no pueda tener un valor nulo.UNIQUE: Esta restricción garantiza que los valores de una columna sean únicos en la tabla.PRIMARY KEY: Esta restricción define una clave primaria en una tabla, que se utilizará como identificador único para cada registro.FOREIGN KEY: Esta restricción establece una relación entre dos tablas utilizando una columna común. Asegura la integridad referencial entre las tablas.CHECK: Esta restricción permite establecer reglas o condiciones que deben cumplirse para los valores almacenados en una columna.
Establecer restricciones y reglas de integridad en tu base de datos es fundamental para garantizar la calidad de los datos almacenados y evitar inconsistencias. Las restricciones mencionadas anteriormente te ayudarán a mantener la integridad referencial, validar los datos ingresados y evitar duplicaciones o valores no deseados en tu base de datos.
Qué implicaciones tienen las relaciones en base de datos a nivel de programación y desarrollo de aplicaciones
Las relaciones en base de datos son fundamentales a nivel de programación y desarrollo de aplicaciones. Cuando se trabaja con bases de datos relacionales, es necesario entender cómo funcionan las relaciones entre tablas para poder diseñar un esquema eficiente y modelar adecuadamente los datos.
En términos generales, una relación se establece cuando hay una conexión o asociación entre dos o más entidades en una base de datos. Estas entidades suelen ser representadas como tablas, donde cada fila representa una instancia u objeto y cada columna representa un atributo o característica de ese objeto.
Existen diferentes tipos de relaciones que se pueden establecer en una base de datos, como la relación uno a muchos (1:N), muchos a muchos (N:M) y uno a uno (1:1). Cada tipo de relación tiene sus propias implicaciones y consideraciones a tener en cuenta al desarrollar una aplicación.
La relación uno a muchos es la más común y significa que un registro de una tabla se asocia con varios registros de otra tabla. Por ejemplo, en una base de datos de una tienda en línea, un cliente puede tener varios pedidos asociados. Esto se representa agregando una clave foránea en la tabla de pedidos que se refiere a la clave primaria de la tabla de clientes.
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT,
fecha_pedido DATE,
FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente)
);
La relación muchos a muchos ocurre cuando varios registros de una tabla están relacionados con varios registros de otra tabla. Para modelar esta relación, se utiliza una tabla intermedia o tabla de unión que contiene las claves primarias de ambas tablas. Por ejemplo, en una base de datos de un blog, varios usuarios pueden tener varios roles asociados.
CREATE TABLE usuarios (
id_usuario INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE roles (
id_rol INT PRIMARY KEY,
nombre VARCHAR(50)
);
CREATE TABLE usuarios_roles (
id_usuario INT,
id_rol INT,
FOREIGN KEY (id_usuario) REFERENCES usuarios(id_usuario),
FOREIGN KEY (id_rol) REFERENCES roles(id_rol)
);
Por último, la relación uno a uno se da cuando un registro de una tabla se relaciona con solo un registro de otra tabla y viceversa. Para representar esta relación, se puede incluir la clave primaria de una tabla como clave foránea en la otra tabla. Por ejemplo, en una base de datos de empleados, cada empleado puede tener una única cuenta de usuario asociada.
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE cuentas (
id_cuenta INT PRIMARY KEY,
id_empleado INT UNIQUE,
username VARCHAR(50),
password VARCHAR(50),
FOREIGN KEY (id_empleado) REFERENCES empleados(id_empleado)
);
Comprender las relaciones en base de datos es esencial para el desarrollo de aplicaciones. El diseño adecuado de las relaciones entre tablas permitirá una gestión eficiente de los datos y la generación de consultas complejas. Además, es importante considerar también las implicaciones de rendimiento y optimización al trabajar con relaciones en base de datos.
¿Qué otras consideraciones debes tener en cuenta al trabajar con relaciones en base de datos?
1. Cardinalidad de las relaciones:
La cardinalidad de una relación se refiere a la cantidad de instancias de una entidad que pueden estar relacionadas con una instancia de otra entidad. Se clasifican en:
- Uno a uno (1:1): Cada instancia de una entidad está asociada a una única instancia de otra entidad.
- Uno a muchos (1:N): Cada instancia de una entidad puede estar relacionada con varias instancias de otra entidad.
- Muchos a uno (N:1): Varias instancias de una entidad están relacionadas con una única instancia de otra entidad.
- Muchos a muchos (N:N): Varias instancias de una entidad pueden estar relacionadas con varias instancias de otra entidad.
2. Clave primaria y clave foránea:
Para establecer una relación entre dos entidades, es necesario utilizar las claves primarias y las claves foráneas. La clave primaria es un atributo único dentro de una entidad que permite identificar de manera unívoca cada instancia. La clave foránea es un atributo que hace referencia a la clave primaria de otra entidad, estableciendo así la relación entre ellas.
3. Tipos de integridad referencial:
Al establecer relaciones entre entidades en una base de datos, es importante garantizar la integridad referencial. Los principales tipos de integridad referencial son:
- Restricción DELETE: Define qué sucede con los registros de una entidad relacionada cuando se elimina un registro en la entidad principal.
- Restricción UPDATE: Define qué sucede con los registros de una entidad relacionada cuando se modifica un registro en la entidad principal.
- Restricción INSERT: Define qué sucede con los registros de una entidad relacionada cuando se inserta un nuevo registro en la entidad principal.
4. Normalización de relaciones:
La normalización es el proceso de organizar las tablas y las relaciones en una base de datos para eliminar la redundancia y mejorar la eficiencia. Existen diferentes formas normales, como la primera forma normal (1NF), segunda forma normal (2NF) y tercera forma normal (3NF), cada una con reglas específicas que deben cumplirse para asegurar una estructura de base de datos óptima.
5. Consultas JOIN:
Las consultas JOIN son utilizadas para combinar datos de múltiples tablas basándose en condiciones relacionales. Las principales consultas JOIN son:
- INNER JOIN: Retorna solamente las filas que tienen coincidencias en ambas tablas involucradas.
- LEFT JOIN: Retorna todas las filas de la tabla izquierda y las coincidentes de la tabla derecha.
- RIGHT JOIN: Retorna todas las filas de la tabla derecha y las coincidentes de la tabla izquierda.
- FULL OUTER JOIN: Retorna todas las filas de ambas tablas, incluyendo las no coincidentes.
Una relación en una base de datos es una conexión lógica entre dos tablas que permite establecer vínculos y realizar consultas relacionadas.
En una relación uno a uno, un registro en una tabla solo puede estar vinculado a un registro en otra tabla, mientras que en una relación uno a muchos, un registro en una tabla puede estar vinculado a varios registros en otra tabla.
Una relación en una base de datos relacional se representa mediante una clave foránea, que es un campo en una tabla que hace referencia al campo clave primaria de otra tabla.
La integridad referencial es una regla que garantiza que los vínculos entre las tablas en una base de datos son válidos y consistentes, evitando la existencia de registros huérfanos o referencias incorrectas.
No, si un registro tiene vínculos con otras tablas mediante una clave foránea, no se puede eliminar directamente el registro. Antes de eliminarlo, se deben eliminar o actualizar los registros relacionados en las otras tablas para mantener la integridad referencial.
Deja una respuesta
Todo lo que debes saber sobre las relaciones en base de datos: guía completa y práctica
Las relaciones en base de datos son fundamentales para organizar y estructurar la información de manera eficiente. En un mundo cada vez más digital, donde se generan grandes volúmenes de datos, es imprescindible contar con sistemas que permitan gestionarlos de forma sistemática y coherente.
Te proporcionaremos una guía completa y práctica sobre las relaciones en base de datos. Explicaremos qué son las relaciones, por qué son importantes, los diferentes tipos de relaciones que existen y cómo se implementan en el modelo entidad-relación. Además, daremos ejemplos claros y sencillos que te ayudarán a comprender mejor este concepto fundamental de la gestión de bases de datos.
- Qué son las relaciones en base de datos y por qué son importantes
- Cuáles son los tipos de relaciones más comunes en base de datos
- Cómo se establecen las relaciones entre tablas en una base de datos relacional
- Cuál es la diferencia entre una relación uno a uno, uno a muchos y muchos a muchos
- Cuándo deberías utilizar una relación uno a uno en tu base de datos
- Cuándo deberías utilizar una relación uno a muchos en tu base de datos
- Cuándo deberías utilizar una relación muchos a muchos en tu base de datos
- Qué es una clave primaria y cómo se utiliza en las relaciones de base de datos
- Cómo se representan las relaciones en un diagrama de entidad-relación
- Cuál es el papel de las llaves foráneas en las relaciones de base de datos
- Cómo se manejan los problemas de integridad referencial en las relaciones de base de datos
- Cuáles son las ventajas y desventajas de usar relaciones en base de datos
- Cómo optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones
- Cómo crear consultas JOIN para recuperar datos de tablas relacionadas
- Cuáles son las mejores prácticas para diseñar y mantener relaciones en una base de datos
- Qué implicaciones tienen las relaciones en base de datos a nivel de programación y desarrollo de aplicaciones
- ¿Qué otras consideraciones debes tener en cuenta al trabajar con relaciones en base de datos?
Qué son las relaciones en base de datos y por qué son importantes
Las relaciones en base de datos son una parte fundamental del diseño y la estructura de cualquier sistema de gestión de bases de datos (SGBD). Son utilizadas para establecer conexiones lógicas entre las tablas de una base de datos, permitiendo así organizar la información de manera eficiente y representar de manera precisa las relaciones existentes entre los diferentes conjuntos de datos.
La importancia de las relaciones en base de datos radica en que nos permiten establecer vínculos entre distintas entidades o tablas dentro de una base de datos. Esto nos permite reflejar relaciones y asociaciones entre los datos de una forma más precisa y coherente.
Además, las relaciones en base de datos facilitan el mantenimiento de la integridad referencial de los datos. Esto significa que se puede garantizar que no se puedan hacer operaciones que violen las reglas definidas en la estructura de la base de datos. Por ejemplo, si tenemos una tabla de "productos" y otra de "pedidos", podemos establecer una relación entre ellas para asegurarnos de que un producto solo pueda ser asociado a un pedido existente.
Tipos de relaciones en base de datos
Existen diferentes tipos de relaciones que se pueden establecer entre las tablas de una base de datos:
- Relación uno a uno: En este tipo de relación, cada registro en la tabla A está asociado con exactamente un registro en la tabla B, y viceversa.
- Relación uno a muchos: En este tipo de relación, cada registro en la tabla A está asociado con cero o más registros en la tabla B, pero cada registro en la tabla B solo está asociado con un único registro en la tabla A.
- Relación muchos a muchos: En este tipo de relación, cada registro en la tabla A puede estar asociado con cero o más registros en la tabla B, y cada registro en la tabla B puede estar asociado con cero o más registros en la tabla A.
Estos son solo algunos de los tipos de relaciones más comunes, pero existen otras variaciones y combinaciones posibles. La elección del tipo de relación adecuada dependerá de las necesidades específicas de cada base de datos y del diseño que se esté implementando.
Cómo establecer relaciones en base de datos
Para establecer relaciones en una base de datos, es necesario definir la clave primaria y la clave foránea en las tablas involucradas.
La clave primaria es un campo o grupo de campos que identifica de forma única cada registro en una tabla. Mientras tanto, la clave foránea es un campo en una tabla que hace referencia a la clave primaria de otra tabla.
Para establecer una relación entre dos tablas, simplemente se debe seleccionar el campo o campos de la clave primaria en la tabla principal y hacerlos coincidir con el campo o campos de la clave foránea en la tabla secundaria.
Una vez que las relaciones se han establecido correctamente, se pueden realizar operaciones de consulta y manipulación de datos que tengan en cuenta estas relaciones para obtener información precisa y coherente.
Consideraciones al utilizar relaciones en base de datos
Aunque las relaciones en base de datos tienen muchas ventajas, también es importante considerar algunas limitaciones y consideraciones:
- Las relaciones en base de datos pueden generar mayor complejidad en el diseño y mantenimiento de la base de datos. Es importante planificar y organizar cuidadosamente las relaciones para evitar posibles problemas de rendimiento o conflicto.
- Es fundamental asegurarse de que se mantenga la integridad referencial de los datos al establecer relaciones en la base de datos. Esto implica garantizar que las operaciones de inserción, actualización y eliminación cumplan con las reglas definidas en la estructura de la base de datos.
- Es necesario tener en cuenta el volumen de datos y las necesidades de rendimiento al diseñar las relaciones en una base de datos. En algunos casos, puede ser más eficiente denormalizar ciertos conjuntos de datos para evitar una excesiva complejidad en las consultas.
Tener en cuenta estas consideraciones nos ayudará a diseñar un sistema de gestión de base de datos sólido y eficiente.
Cuáles son los tipos de relaciones más comunes en base de datos
En las bases de datos, los tipos de relaciones más comunes son:
Relación uno a uno (1:1)
En este tipo de relación, un registro de una tabla se relaciona con exactamente un registro de otra tabla, y viceversa. Es decir, cada registro de una tabla está relacionado directamente con un único registro de la otra tabla.
Por ejemplo, supongamos que tenemos dos tablas: Personas y Direcciones. Cada persona puede tener solo una dirección, y cada dirección está asociada a una sola persona. Por lo tanto, habrá una relación uno a uno entre estas dos tablas.
Relación uno a muchos (1:N)
En este tipo de relación, un registro de una tabla se relaciona con uno o varios registros de otra tabla, pero los registros de la segunda tabla solo se relacionan con un único registro de la primera tabla.
Por ejemplo, consideremos las tablas Clientes y Pedidos. Un cliente puede realizar varios pedidos, pero cada pedido está asociado a un único cliente. Por lo tanto, hay una relación uno a muchos entre estas dos tablas.
Relación muchos a muchos (N:N)
En este tipo de relación, múltiples registros de una tabla pueden estar relacionados con múltiples registros de otra tabla y viceversa.
Para lograr esto, se utiliza una tabla intermedia, también conocida como tabla de unión o tabla puente. Esta tabla incluye las claves primarias de ambas tablas para establecer las relaciones entre ellas.
Por ejemplo, consideremos las tablas Estudiantes y Cursos. Un estudiante puede estar matriculado en varios cursos y, a su vez, un curso puede tener varios estudiantes. Para representar esta relación, se utilizará una tabla de unión que contenga las claves primarias de ambas tablas.
Existen otros tipos de relaciones menos comunes, como la relación recursiva (una tabla se relaciona consigo misma) y la relación polimórfica (varias tablas pueden relacionarse con una tabla en común), pero los mencionados anteriormente son los más utilizados y conocidos en las bases de datos.
Cómo se establecen las relaciones entre tablas en una base de datos relacional
En una base de datos relacional, las relaciones entre tablas se establecen a través de claves primarias y claves externas (o claves foráneas). Estas claves permiten vincular los registros de una tabla con los de otra, creando así una relación entre ellas.
La clave primaria es un campo o conjunto de campos que identifican de manera única cada registro en una tabla. Suele ser un número autoincremental o un valor único asignado por el sistema. Por ejemplo, en una tabla de usuarios, la clave primaria puede ser el campo "ID_usuario".
Por otro lado, la clave externa es un campo en una tabla que hace referencia a la clave primaria de otra tabla. Esto crea una relación entre las dos tablas, donde el campo con la clave externa actúa como un enlace hacia la tabla referenciada. Por ejemplo, si tenemos una tabla de pedidos y otra de clientes, podemos utilizar la clave externa "ID_cliente" en la tabla de pedidos para relacionar cada pedido con el cliente correspondiente.
Ejemplo de cómo se establece una relación entre tablas
Supongamos que tenemos dos tablas: "clientes" y "pedidos". La tabla "clientes" tiene los siguientes campos:
ID_cliente: clave primarianombreemail
La tabla "pedidos" tiene los siguientes campos:
ID_pedido: clave primariaID_cliente: clave externaproductocantidadprecio
En este caso, la clave externa ID_cliente en la tabla "pedidos" hace referencia a la clave primaria ID_cliente en la tabla "clientes". Esto permite establecer una relación entre los pedidos y los clientes, de manera que cada pedido esté asociado a un cliente específico.
Tipo de relaciones en base de datos
Existen diferentes tipos de relaciones que se pueden establecer entre tablas en una base de datos relacional:
- Relación uno a uno: cada registro de una tabla está relacionado con exactamente un registro de otra tabla. Por ejemplo, si tenemos una tabla de empleados y otra de direcciones, cada empleado puede tener una sola dirección y cada dirección está asociada a un solo empleado.
- Relación uno a muchos: cada registro de una tabla está relacionado con varios registros de otra tabla. Por ejemplo, si tenemos una tabla de departamentos y otra de empleados, cada departamento puede tener varios empleados pero cada empleado solo pertenece a un departamento.
- Relación muchos a muchos: varios registros de una tabla están relacionados con varios registros de otra tabla. Para modelar esta relación se requiere de una tabla intermedia (también conocida como tabla de unión o tabla puente) que contiene las claves primarias de ambas tablas. Por ejemplo, si tenemos una tabla de estudiantes y otra de cursos, la tabla intermedia podría ser "matrículas", donde se registrarían las asignaciones de estudiantes a cursos.
Estas son solo algunas de las posibles formas de establecer relaciones entre tablas en una base de datos relacional. La elección del tipo de relación dependerá de la estructura y los requerimientos específicos de cada sistema.
Cuál es la diferencia entre una relación uno a uno, uno a muchos y muchos a muchos
Una de las primeras cosas que debes entender cuando trabajas con bases de datos es el concepto de relaciones. Las relaciones son vínculos entre diferentes tablas en una base de datos. Hay tres tipos principales de relaciones: uno a uno, uno a muchos y muchos a muchos.
Relación uno a uno
En una relación uno a uno, un registro en una tabla está relacionado con exactamente un registro en otra tabla, y viceversa. Esto significa que la relación es única y recíproca. Un ejemplo común de una relación uno a uno es una tabla de "empleados" y una tabla de "datos personales". Cada empleado tiene una sola entrada en la tabla de datos personales y viceversa.
Relación uno a muchos
En una relación uno a muchos, un registro en una tabla se relaciona con varios registros en otra tabla, pero los registros en la segunda tabla solo están relacionados con un único registro en la primera tabla. Esta es la relación más común en las bases de datos y se utiliza para representar conexiones como "un autor tiene muchos libros".
Relación muchos a muchos
En una relación muchos a muchos, múltiples registros en una tabla pueden estar relacionados con múltiples registros en otra tabla. Para representar esta relación, se utiliza una tabla intermedia que contiene las claves primarias de ambas tablas para establecer la conexión. Por ejemplo, en una base de datos de una tienda en línea, puede haber una tabla de "productos" y una tabla de "categorias". Varios productos pueden pertenecer a varias categorías y viceversa.
Cuándo deberías utilizar una relación uno a uno en tu base de datos
Una relación uno a uno en una base de datos se utiliza cuando necesitas relacionar dos entidades o tablas de manera que cada registro de una tabla esté relacionado con exactamente un registro de la otra tabla. Esto se logra mediante el uso de claves primarias y claves foráneas.
Existen varias situaciones en las cuales puede ser adecuado utilizar una relación uno a uno en tu base de datos:
- Cuando tienes información adicional sobre un registro que no quieres almacenar en la misma tabla para mantenerla ordenada y evitar la duplicación de datos. Por ejemplo, si tienes una tabla de "Usuarios" y quieres almacenar información de contacto como dirección, teléfono, etc., podrías crear una tabla separada de "Contacto" con una relación uno a uno donde cada registro de "Usuario" tenga una única asociación con "Contacto". Esto te permitirá tener información más organizada y evitará tener campos vacíos en la tabla principal.
- Cuando quieres separar información sensible o confidencial. En algunos casos, puedes tener información en tu base de datos que sea considerada más sensible o privada que el resto de los datos. Al separar esta información en una tabla adicional y establecer una relación uno a uno, puedes aplicar medidas de seguridad adicionales a esta tabla específica, como cifrado o restricciones de acceso más estrictas.
- Cuando la información adicional puede no estar siempre presente. Hay ocasiones en las que cierta información es opcional o simplemente puede no estar disponible para todos los registros. En lugar de dejar campos vacíos en la tabla principal, puedes almacenar esta información en una tabla secundaria y establecer una relación uno a uno. De esta manera, solo los registros que tienen información adicional estarán asociados con la tabla secundaria, lo que te permite ahorrar espacio y mejorar el rendimiento de las consultas.
- Cuando necesitas dividir una entidad en subentidades más especializadas. En algunos casos, una entidad puede tener atributos o características adicionales que solo son relevantes para un subconjunto específico de registros. Al crear una relación uno a uno entre la entidad principal y una tabla secundaria, puedes almacenar estos atributos adicionales solo para los registros correspondientes y mantener la integridad y coherencia de tus datos.
En definitiva, utilizar una relación uno a uno en tu base de datos puede ser beneficioso para organizar y mantener la integridad de tus datos, salvaguardar información sensible y optimizar el rendimiento de las consultas. Sin embargo, debes evaluar cuidadosamente cada caso y considerar si realmente es necesario antes de implementarla en tu diseño de base de datos.
Cuándo deberías utilizar una relación uno a muchos en tu base de datos
Una relación uno a muchos en una base de datos se utiliza cuando tienes una entidad principal que está relacionada con múltiples entidades secundarias. Esta relación es comúnmente representada por una llave externa en la tabla secundaria que refiere a la llave primaria de la tabla principal. En otras palabras, para cada registro en la tabla principal, puede haber varios registros asociados en la tabla secundaria.
Existen varias situaciones en las que es recomendable utilizar una relación uno a muchos en tu base de datos. Algunos ejemplos son:
- Relación entre usuarios y publicaciones: Imagina que estás desarrollando una aplicación de blog donde los usuarios pueden crear publicaciones. Cada usuario puede tener múltiples publicaciones asociadas a su cuenta. En este caso, sería apropiado utilizar una relación uno a muchos entre la tabla de usuarios y la tabla de publicaciones. La llave primaria en la tabla de usuarios se convertiría en la llave externa en la tabla de publicaciones.
- Relación entre un cliente y sus pedidos: Si estás creando un sistema de comercio electrónico, es probable que tengas una tabla de clientes y una tabla de pedidos. Cada cliente puede realizar múltiples pedidos, por lo que una relación uno a muchos sería adecuada en este caso. La llave primaria en la tabla de clientes se utilizaría como llave externa en la tabla de pedidos.
- Relación entre una categoría y sus productos: Supongamos que estás construyendo una tienda en línea donde tienes diferentes categorías de productos y cada categoría contiene varios productos. En este caso, una relación uno a muchos entre la tabla de categorías y la tabla de productos sería la opción correcta. La llave primaria en la tabla de categorías se convertiría en la llave externa en la tabla de productos.
Es importante tener en cuenta que una relación uno a muchos es solo uno de los tipos de relaciones disponibles en bases de datos. Dependiendo de tu aplicación y requerimientos, podrías necesitar utilizar otros tipos de relaciones como las relaciones muchos a muchos o las relaciones uno a uno.
Utilizar una relación uno a muchos en tu base de datos es apropiado cuando necesitas relacionar una entidad principal con múltiples entidades secundarias. Esta relación puede ser útil en escenarios como usuarios y publicaciones, clientes y pedidos, o categorías y productos.
Cuándo deberías utilizar una relación muchos a muchos en tu base de datos
Una relación muchos a muchos se utiliza cuando deseas representar una asociación entre dos entidades en tu base de datos donde ambas entidades pueden tener múltiples instancias relacionadas entre sí. Este tipo de relación es especialmente útil cuando existe una correspondencia de muchos a muchos en la vida real.
Para entenderlo mejor, considera el ejemplo de una aplicación de gestión de proyectos. En este caso, puedes tener una entidad de "Proyecto" y otra entidad de "Empleado". Cada proyecto puede estar asignado a varios empleados y cada empleado puede trabajar en varios proyectos diferentes. Aquí es donde una relación muchos a muchos sería apropiada.
En términos de diseño de base de datos, una relación muchos a muchos generalmente se implementa mediante el uso de una tabla de relación intermedia. Esta tabla actúa como un enlace entre las dos entidades principales y contiene las claves primarias de ambos lados de la relación.
Por ejemplo, en el caso del ejemplo de la gestión de proyectos, podríamos tener una tabla llamada "Asignaciones" con columnas como "ID del Proyecto", "ID del Empleado" y cualquier otra información relevante sobre la asignación en particular.
Al utilizar una relación muchos a muchos, puedes representar eficientemente esta asociación compleja en tu base de datos sin redundancia ni inconsistencias en los datos.
Qué es una clave primaria y cómo se utiliza en las relaciones de base de datos
Una clave primaria en una base de datos es un campo o conjunto de campos que identifica de manera única cada registro en una tabla. Se utiliza para garantizar la integridad y consistencia de los datos, ya que no puede haber duplicados en la clave primaria. La clave primaria se define al crear la tabla y suele ser autoincremental, lo que significa que se genera automáticamente un valor único para cada nuevo registro insertado.
Para utilizar una clave primaria en las relaciones de base de datos, se debe establecer una relación entre tablas utilizando esta clave. En la tabla principal, se define la clave primaria como un campo y en la tabla secundaria, se define la clave primaria como una clave externa o clave foránea.
Ejemplo práctico de uso de clave primaria en una relación de base de datos
Supongamos que tenemos dos tablas en una base de datos: "Clientes" y "Pedidos". La tabla "Clientes" tiene una clave primaria llamada "id_cliente", que es un número único para cada cliente. La tabla "Pedidos" tiene una clave primaria llamada "id_pedido" y también tiene un campo llamado "cliente_id" que hace referencia a la clave primaria de la tabla "Clientes". De esta manera, se establece una relación entre las tablas.
CREATE TABLE Clientes (
id_cliente INT PRIMARY KEY AUTO_INCREMENT,
nombre VARCHAR(50),
telefono VARCHAR(15)
);
CREATE TABLE Pedidos (
id_pedido INT PRIMARY KEY AUTO_INCREMENT,
cliente_id INT,
fecha_pedido DATE
);
ALTER TABLE Pedidos ADD FOREIGN KEY (cliente_id) REFERENCES Clientes(id_cliente);
En el ejemplo anterior, se crea la tabla "Clientes" con una clave primaria de tipo entero autoincremental. Luego, se crea la tabla "Pedidos" con una clave primaria de tipo entero autoincremental y un campo "cliente_id" que hace referencia a la clave primaria de la tabla "Clientes". Por último, se agrega una restricción de clave foránea para garantizar la integridad referencial entre las tablas.
De esta manera, cada vez que se inserta un nuevo pedido en la tabla "Pedidos", se debe especificar el ID del cliente al que pertenece ese pedido. Esto permite establecer una relación entre los clientes y sus pedidos, y realizar consultas que involucren datos de ambas tablas.
Cómo se representan las relaciones en un diagrama de entidad-relación
En un diagrama de entidad-relación, las relaciones se representan mediante líneas que conectan las entidades involucradas. Estas líneas indican la existencia de una relación entre las entidades y pueden tener diferentes características según el tipo de relación.
Tipo de relaciones
Existen varios tipos de relaciones que se pueden representar en un diagrama de entidad-relación:
- Relación uno a uno (1:1): Este tipo de relación indica que una entidad está asociada con otra entidad de forma exclusiva. Se representa con una línea recta que une las dos entidades.
- Relación uno a muchos (1:N): En este caso, una entidad puede estar asociada con múltiples instancias de otra entidad. Se representa con una línea de rombo entre las dos entidades, donde el rombo apunta hacia la entidad "uno" y la línea se dirige hacia la entidad "muchos".
- Relación muchos a uno (N:1): Es similar a la relación uno a muchos, pero en orden inverso. Esto significa que varias instancias de una entidad se vinculan con una sola instancia de otra entidad. La representación es la misma que en la relación uno a muchos.
- Relación muchos a muchos (N:N): En este caso, múltiples instancias de una entidad pueden estar asociadas con múltiples instancias de otra entidad. Se representa con un rombo que apunta hacia ambas entidades y una línea que conecta los rombos.
Atributos de las relaciones
Además de representar el tipo de relación, también se pueden agregar atributos a las relaciones en un diagrama de entidad-relación. Estos atributos son propiedades o características específicas de la relación que pueden brindar más información sobre cómo se relacionan las entidades.
Por ejemplo, si estamos modelando una relación entre las entidades "Cliente" y "Pedido", podríamos agregar el atributo "fecha" a la relación para indicar cuándo se realizó el pedido. Otros ejemplos de atributos podrían ser "cantidad" para indicar la cantidad de productos solicitados en el pedido o "estado" para indicar si el pedido está pendiente, en proceso o completado.
Cardinalidad de las relaciones
La cardinalidad de una relación indica cuántas instancias de una entidad están involucradas en la relación con respecto a las instancias de la otra entidad.
Cuál es el papel de las llaves foráneas en las relaciones de base de datos
Las llaves foráneas son un componente fundamental en las relaciones de base de datos. Son utilizadas para establecer y mantener la integridad referencial entre dos tablas. En términos simples, una llave foránea es una columna o conjunto de columnas en una tabla que hace referencia a la clave primaria de otra tabla.
Al utilizar llaves foráneas, se pueden establecer relaciones entre diferentes tablas en una base de datos, lo que permite almacenar y vincular información de manera eficiente y precisa. Estas relaciones se basan en la idea de que una llave foránea (o conjunto de ellas) en una tabla apunta a la clave primaria de otra tabla, lo que implica una conexión lógica entre los datos de ambas tablas.
Cómo se definen las llaves foráneas
Para definir una llave foránea en una tabla, se utiliza la cláusula FOREIGN KEY seguida del nombre de la columna (o conjunto de columnas) que actuará como llave foránea y la cláusula REFERENCES con el nombre de la tabla y columna(s) de la clave primaria a la que se está haciendo referencia. Por ejemplo:
CREATE TABLE tabla1 (
id_tabla1 INT PRIMARY KEY,
columna1 VARCHAR(50),
id_tabla2 INT FOREIGN KEY REFERENCES tabla2(id_tabla2)
);
En este ejemplo, la tabla "tabla1" tiene una llave primaria llamada "id_tabla1" y una llave foránea llamada "id_tabla2" que hace referencia a la tabla "tabla2" y su clave primaria "id_tabla2". Esto establece una relación entre las dos tablas.
Tipos de restricciones en llaves foráneas
Las llaves foráneas pueden tener diferentes tipos de restricciones, que ayudan a garantizar la integridad referencial y evitar inconsistencias en los datos. Algunas de las restricciones comunes son:
- ON DELETE CASCADE: Si se elimina una fila en la tabla referenciada, todas las filas relacionadas en la tabla que contiene la llave foránea también se eliminan automáticamente.
- ON UPDATE CASCADE: Si se actualiza el valor de una fila en la columna referenciada, todas las filas relacionadas en la tabla que contiene la llave foránea se actualizan automáticamente.
- ON DELETE SET NULL: Si se elimina una fila en la tabla referenciada, el valor de la llave foránea en la tabla que la contiene se establecerá como NULL.
- ON UPDATE SET NULL: Si se actualiza el valor de una fila en la columna referenciada, el valor de la llave foránea en la tabla que la contiene se establecerá como NULL.
- ON DELETE RESTRICT: No se permite eliminar una fila en la tabla referenciada si hay filas relacionadas en la tabla que contiene la llave foránea.
- ON UPDATE RESTRICT: No se permite actualizar el valor de una fila en la columna referenciada si hay filas relacionadas en la tabla que contiene la llave foránea.
Estas restricciones se definen al momento de crear la llave foránea y ayudan a mantener la integridad de los datos en las relaciones de base de datos.
Cómo se manejan los problemas de integridad referencial en las relaciones de base de datos
Los problemas de integridad referencial son situaciones en las que los datos almacenados en una base de datos relacionales no cumplen con ciertas restricciones o reglas definidas en la estructura de las relaciones. Estos problemas pueden ocurrir cuando se intenta insertar, actualizar o eliminar datos en una tabla relacionada sin respetar las dependencias establecidas.
Existen diferentes formas de manejar los problemas de integridad referencial en las relaciones de base de datos. A continuación, se presentan algunas técnicas y prácticas comunes utilizadas para garantizar que la integridad de los datos sea mantenida correctamente:
1. Restricciones de clave primaria y clave foránea
Las restricciones de clave primaria y clave foránea son uno de los métodos más comunes para mantener la integridad referencial en una base de datos. La clave primaria es un campo o combinación de campos que identifica de forma única cada registro en una tabla. La clave foránea, por otro lado, es un campo o combinación de campos que hace referencia a una clave primaria en otra tabla. Al establecer estas restricciones, se asegura que solo se puedan insertar o actualizar registros si se cumple con las dependencias establecidas.
CREATE TABLE usuarios (
id INT PRIMARY KEY,
nombre VARCHAR(50)
);
CREATE TABLE compras (
id INT PRIMARY KEY,
usuario_id INT,
producto VARCHAR(50),
FOREIGN KEY (usuario_id) REFERENCES usuarios(id)
);
En el ejemplo anterior, la tabla "compras" tiene una clave foránea ("usuario_id") que hace referencia a la clave primaria ("id") de la tabla "usuarios". Esto garantiza que solo se puedan ingresar registros en la tabla "compras" si existe un registro correspondiente en la tabla "usuarios".
2. Reglas de cascada
Las reglas de cascada son utilizadas cuando se desea definir el efecto que debe tener una operación (como una inserción o eliminación) en las tablas relacionadas. Las opciones más comunes son:
- CASCADE: cuando se realiza una operación, se propagan los cambios a las tablas relacionadas.
- RESTRICT: se impide la realización de una operación si viola la integridad referencial.
- SET NULL: se establece el valor de la clave foránea en NULL si el registro relacionado es eliminado.
- SET DEFAULT: se establece el valor de la clave foránea en su valor predeterminado si el registro relacionado es eliminado.
Estas reglas ayudan a mantener la coherencia y consistencia de los datos en las relaciones.
3. Transacciones y bloqueo de datos
Otra forma de manejar la integridad referencial en las relaciones de base de datos es utilizando transacciones y bloqueo de datos. Una transacción es una secuencia de operaciones que se ejecutan como una sola unidad lógica de trabajo. En este contexto, las operaciones pueden incluir inserciones, actualizaciones o eliminaciones de datos en las tablas relacionadas.
El bloqueo de datos, por otro lado, es una técnica utilizada para evitar que múltiples usuarios realicen cambios simultáneos en los mismos datos. Cuando se realiza una transacción en una base de datos, se pueden aplicar bloqueos para garantizar que otros usuarios no puedan modificar los datos relacionados hasta que la transacción se complete correctamente.
El uso adecuado de las transacciones y el bloqueo de datos puede ayudar a evitar problemas de integridad referencial al asegurar que las operaciones se realicen de manera secuencial y controlada.
Cuáles son las ventajas y desventajas de usar relaciones en base de datos
Las relaciones en base de datos permiten establecer conexiones entre diferentes tablas, lo que agrega flexibilidad y eficiencia al manejar grandes cantidades de datos. Aunque las relaciones pueden ser beneficiosas, también tienen algunas desventajas a considerar.
Ventajas de usar relaciones en base de datos:
- Eliminación de la redundancia de datos: Al utilizar relaciones, se evita la duplicación innecesaria de información en múltiples lugares, lo que ayuda a mantener una base de datos más consistente y fácil de mantener. Esto es especialmente útil cuando se necesita actualizar o modificar el dato relacionado en varios lugares.
- Integridad referencial: Las relaciones en base de datos permiten establecer restricciones y reglas que aseguran que los datos relacionados sean consistentes y correctos. Por ejemplo, se puede definir que un registro en una tabla (tabla secundaria) solo puede existir si existe otro registro en otra tabla (tabla principal).
- Escalabilidad: Las relaciones permiten ampliar la base de datos y agregar nuevas tablas sin afectar directamente las ya existentes. Esto facilita la gestión del crecimiento de la base de datos a medida que se agregan nuevos registros y se realizan cambios en la estructura.
- Análisis de datos complejos: Al utilizar relaciones, es posible realizar consultas y análisis de datos complejos mediante el uso de JOINs y otras operaciones relacionales. Esto es especialmente útil cuando se requiere extraer información de múltiples tablas de forma eficiente.
Desventajas de usar relaciones en base de datos:
- Complejidad: Utilizar relaciones en base de datos agrega un nivel adicional de complejidad tanto en el diseño como en la consulta de los datos. Es necesario comprender y aplicar correctamente las claves primarias, foráneas y las reglas de integridad referencial.
- Mayor tiempo de ejecución: Las consultas que involucran varias tablas pueden requerir más tiempo para ejecutarse que aquellas que solo manipulan una tabla. Esto se debe a la necesidad de unir o combinar la información de múltiples tablas.
- Posible pérdida de rendimiento: Una mala administración de las relaciones puede llevar a una disminución en el rendimiento de la base de datos. Por ejemplo, si hay una alta cantidad de JOINs innecesarios o mal diseñados, esto puede causar cuellos de botella y ralentizar la consulta de datos.
- Mayor complejidad en la migración y actualización: Cuando se realizan cambios en la estructura o esquema de la base de datos, como agregar o eliminar tablas o modificar relaciones existentes, puede ser complicado realizar la migración y actualización sin afectar la integridad de los datos existentes.
A pesar de estas desventajas, en la mayoría de los casos, las ventajas de utilizar relaciones en una base de datos superan con creces las desventajas. Sin embargo, es importante evaluar cuidadosamente las necesidades y requerimientos específicos del proyecto antes de decidir si utilizar o no relaciones en base de datos.
Cómo optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones
Cuando trabajamos con bases de datos relacionales, una de las preocupaciones más comunes es el rendimiento de las consultas. Las relaciones entre tablas pueden afectar significativamente la velocidad de ejecución de las consultas y, por lo tanto, es importante optimizarlas adecuadamente.
Existen varias técnicas que podemos utilizar para mejorar el rendimiento de las consultas en bases de datos relacionales con relaciones. A continuación, se presentan algunas de las mejores prácticas a tener en cuenta:
1. Utilizar índices adecuados
Un índice es una estructura de datos que mejora la velocidad de recuperación de registros en una tabla. Al crear índices en las columnas que se utilizan frecuentemente en las consultas, se puede reducir el tiempo de búsqueda y mejorar el rendimiento general del sistema.
Es importante analizar detenidamente las consultas más comunes y determinar qué columnas son utilizadas con mayor frecuencia. Estas columnas deben ser candidatas a tener índices. Sin embargo, es necesario tener en cuenta que los índices también ocupan espacio en disco, por lo que es importante equilibrar la cantidad de índices creados con el impacto en el rendimiento y almacenamiento.
2. Utilizar claves primarias y foráneas correctamente
Las claves primarias y foráneas son elementos fundamentales en la creación de relaciones entre tablas. Una clave primaria es única en una tabla y se utiliza para identificar de manera única cada registro. Las claves foráneas se utilizan para establecer relaciones entre tablas.
Al utilizar claves primarias y foráneas correctamente, se pueden optimizar las operaciones de inserción, actualización y eliminación en las tablas relacionadas. Esto se debe a que las claves primarias y foráneas permiten que la base de datos realice comprobaciones de integridad referencial de manera eficiente.
3. Evitar consultas innecesarias
Es importante evitar realizar consultas innecesarias, ya que esto puede afectar negativamente el rendimiento del sistema. Para lograr esto, es recomendable analizar y optimizar las consultas existentes antes de ejecutarlas en producción.
Una forma de evitar consultas innecesarias es utilizando técnicas de optimización de consultas, como el uso de índices adecuados, la normalización de la estructura de la base de datos y la utilización de claves foráneas correctamente.
4. Utilizar joins eficientes
Los joins se utilizan para combinar registros de dos o más tablas basándose en una columna común. Sin embargo, dependiendo de cómo se utilicen los joins, pueden generar consultas lentas y pesadas.
Para asegurar un rendimiento óptimo, es importante utilizar los joins de manera eficiente. Esto implica seleccionar el tipo de join adecuado (inner join, left join, right join, etc.) y definir correctamente las condiciones de unión.
SELECT *
FROM tabla1
JOIN tabla2 ON tabla1.columna = tabla2.columna
WHERE condicion
En el ejemplo anterior, "tabla1" y "tabla2" son las tablas que queremos combinar y "columna" es la columna común utilizada para unir las tablas. La "condicion" es opcional y puede filtrar los registros que queremos obtener.
5. Utilizar vistas materializadas
Una vista materializada es una tabla precalculada que almacena el resultado de una consulta compleja. Usar vistas materializadas puede mejorar significativamente el rendimiento de las consultas, especialmente cuando la consulta es costosa en términos de tiempo de ejecución.
Al utilizar vistas materializadas, se reduce el tiempo necesario para ejecutar una consulta compleja porque los resultados ya están almacenados en una tabla. Sin embargo, es importante tener en cuenta que las vistas materializadas ocupan espacio en disco y deben ser actualizadas periódicamente para mantener la información actualizada.
- Optimizar el rendimiento de las consultas en bases de datos relacionales con relaciones requiere tomar en consideración varios aspectos importantes:
- Utilizar índices adecuados para acelerar las búsquedas
- Utilizar claves primarias y foráneas correctamente para optimizar operaciones de inserción, actualización y eliminación/li>
- Avoid consultar innecesariamente
- Utilizar joins eficientes para combinar registros de manera óptima
- Utilizar vistas materializadas para aprovechar resultados precalculados
Cómo crear consultas JOIN para recuperar datos de tablas relacionadas
Una de las características más importantes de las bases de datos relacionales es la capacidad de crear relaciones entre tablas y recuperar datos combinados utilizando consultas JOIN. Esto permite que los datos se extraigan de múltiples tablas y se combinen en una sola vista, lo que facilita el análisis y la visualización de la información.
Existen diferentes tipos de JOIN que se pueden utilizar para combinar datos de múltiples tablas:
INNER JOIN
El INNER JOIN devuelve solo los registros que tienen coincidencias en ambas tablas. Solo se devuelven los registros donde la clave de la primera tabla coincide con la clave de la segunda tabla definida en la cláusula ON.
SELECT columna1, columna2, ...
FROM tabla1
INNER JOIN tabla2
ON tabla1.columna = tabla2.columna;
LEFT JOIN
El LEFT JOIN devuelve todos los registros de la tabla izquierda (tabla1) y los registros coincidentes de la tabla derecha (tabla2). Si no hay coincidencias, se devuelven valores NULL para las columnas de la tabla derecha.
SELECT columna1, columna2, ...
FROM tabla1
LEFT JOIN tabla2
ON tabla1.columna = tabla2.columna;
RIGHT JOIN
El RIGHT JOIN devuelve todos los registros de la tabla derecha (tabla2) y los registros coincidentes de la tabla izquierda (tabla1). Si no hay coincidencias, se devuelven valores NULL para las columnas de la tabla izquierda.
SELECT columna1, columna2, ...
FROM tabla1
RIGHT JOIN tabla2
ON tabla1.columna = tabla2.columna;
FULL JOIN
El FULL JOIN devuelve todos los registros de ambas tablas, incluidos los registros que no tienen coincidencias en la otra tabla. Si no hay coincidencias, se devuelven valores NULL para las columnas sin correspondencia.
SELECT columna1, columna2, ...
FROM tabla1
FULL JOIN tabla2
ON tabla1.columna = tabla2.columna;
Además, es importante tener en cuenta que también se pueden usar combinaciones múltiples de JOIN en una sola consulta. Esto permite combinar más de dos tablas y recuperar datos de acuerdo a las condiciones definidas en la cláusula ON.
Las consultas JOIN son una herramienta poderosa para recuperar datos de tablas relacionadas. Proporcionan flexibilidad y eficiencia al permitirnos combinar información de forma sencilla y obtener resultados precisos para nuestros análisis.
Cuáles son las mejores prácticas para diseñar y mantener relaciones en una base de datos
Cuando se trata de diseñar y mantener relaciones en una base de datos, es importante seguir las mejores prácticas para garantizar un rendimiento óptimo y evitar problemas futuros. En esta guía completa y práctica, te mostraremos algunas recomendaciones clave para diseñar y mantener relaciones en tu base de datos.
1. Normalización de la base de datos
Una de las mejores prácticas para el diseño de relaciones en una base de datos es seguir los principios de normalización. La normalización ayuda a evitar la redundancia de datos y mejora la integridad de la base de datos. Hay diferentes formas normales que debes seguir, desde la primera forma normal (1NF) hasta la tercera forma normal (3NF) y más allá si es necesario. Al seguir estas formas normales, podrás reducir la duplicación de datos y hacer que tus relaciones sean más eficientes.
2. Definición adecuada de las claves primarias y foráneas
Otra práctica importante es asegurarse de definir correctamente las claves primarias y foráneas en tus tablas. Las claves primarias son únicas y se utilizan para identificar de manera única cada registro en una tabla. Por otro lado, las claves foráneas se utilizan para establecer relaciones entre tablas y asegurarse de que los datos estén correctamente vinculados.
Es crucial que las claves primarias sean únicas y no nulas, mientras que las claves foráneas deben estar correctamente definidas para asegurar la integridad referencial de los datos. Además, es importante establecer índices en estas claves para mejorar el rendimiento de las consultas.
3. Uso adecuado de los tipos de datos
Seleccionar los tipos de datos adecuados para tus columnas es otro aspecto crítico del diseño de relaciones en una base de datos. Utilizar los tipos de datos correctos no solo ahorra espacio y mejora el rendimiento, sino que también asegura la validez y consistencia de los datos almacenados.
Es importante utilizar tipos de datos apropiados para cada columna en función de su propósito y contenido. Por ejemplo, utilizar el tipo de datos adecuado para almacenar fechas y horas, así como utilizar tipos numéricos precisos para valores numéricos. Esto ayudará a evitar problemas de almacenamiento y agilizará las operaciones de consulta.
4. Establecimiento de restricciones y reglas de integridad
NOT NULL: Esta restricción garantiza que un campo no pueda tener un valor nulo.UNIQUE: Esta restricción garantiza que los valores de una columna sean únicos en la tabla.PRIMARY KEY: Esta restricción define una clave primaria en una tabla, que se utilizará como identificador único para cada registro.FOREIGN KEY: Esta restricción establece una relación entre dos tablas utilizando una columna común. Asegura la integridad referencial entre las tablas.CHECK: Esta restricción permite establecer reglas o condiciones que deben cumplirse para los valores almacenados en una columna.
Establecer restricciones y reglas de integridad en tu base de datos es fundamental para garantizar la calidad de los datos almacenados y evitar inconsistencias. Las restricciones mencionadas anteriormente te ayudarán a mantener la integridad referencial, validar los datos ingresados y evitar duplicaciones o valores no deseados en tu base de datos.
Qué implicaciones tienen las relaciones en base de datos a nivel de programación y desarrollo de aplicaciones
Las relaciones en base de datos son fundamentales a nivel de programación y desarrollo de aplicaciones. Cuando se trabaja con bases de datos relacionales, es necesario entender cómo funcionan las relaciones entre tablas para poder diseñar un esquema eficiente y modelar adecuadamente los datos.
En términos generales, una relación se establece cuando hay una conexión o asociación entre dos o más entidades en una base de datos. Estas entidades suelen ser representadas como tablas, donde cada fila representa una instancia u objeto y cada columna representa un atributo o característica de ese objeto.
Existen diferentes tipos de relaciones que se pueden establecer en una base de datos, como la relación uno a muchos (1:N), muchos a muchos (N:M) y uno a uno (1:1). Cada tipo de relación tiene sus propias implicaciones y consideraciones a tener en cuenta al desarrollar una aplicación.
La relación uno a muchos es la más común y significa que un registro de una tabla se asocia con varios registros de otra tabla. Por ejemplo, en una base de datos de una tienda en línea, un cliente puede tener varios pedidos asociados. Esto se representa agregando una clave foránea en la tabla de pedidos que se refiere a la clave primaria de la tabla de clientes.
CREATE TABLE clientes (
id_cliente INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE pedidos (
id_pedido INT PRIMARY KEY,
id_cliente INT,
fecha_pedido DATE,
FOREIGN KEY (id_cliente) REFERENCES clientes(id_cliente)
);
La relación muchos a muchos ocurre cuando varios registros de una tabla están relacionados con varios registros de otra tabla. Para modelar esta relación, se utiliza una tabla intermedia o tabla de unión que contiene las claves primarias de ambas tablas. Por ejemplo, en una base de datos de un blog, varios usuarios pueden tener varios roles asociados.
CREATE TABLE usuarios (
id_usuario INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE roles (
id_rol INT PRIMARY KEY,
nombre VARCHAR(50)
);
CREATE TABLE usuarios_roles (
id_usuario INT,
id_rol INT,
FOREIGN KEY (id_usuario) REFERENCES usuarios(id_usuario),
FOREIGN KEY (id_rol) REFERENCES roles(id_rol)
);
Por último, la relación uno a uno se da cuando un registro de una tabla se relaciona con solo un registro de otra tabla y viceversa. Para representar esta relación, se puede incluir la clave primaria de una tabla como clave foránea en la otra tabla. Por ejemplo, en una base de datos de empleados, cada empleado puede tener una única cuenta de usuario asociada.
CREATE TABLE empleados (
id_empleado INT PRIMARY KEY,
nombre VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE cuentas (
id_cuenta INT PRIMARY KEY,
id_empleado INT UNIQUE,
username VARCHAR(50),
password VARCHAR(50),
FOREIGN KEY (id_empleado) REFERENCES empleados(id_empleado)
);
Comprender las relaciones en base de datos es esencial para el desarrollo de aplicaciones. El diseño adecuado de las relaciones entre tablas permitirá una gestión eficiente de los datos y la generación de consultas complejas. Además, es importante considerar también las implicaciones de rendimiento y optimización al trabajar con relaciones en base de datos.
¿Qué otras consideraciones debes tener en cuenta al trabajar con relaciones en base de datos?
1. Cardinalidad de las relaciones:
La cardinalidad de una relación se refiere a la cantidad de instancias de una entidad que pueden estar relacionadas con una instancia de otra entidad. Se clasifican en:
- Uno a uno (1:1): Cada instancia de una entidad está asociada a una única instancia de otra entidad.
- Uno a muchos (1:N): Cada instancia de una entidad puede estar relacionada con varias instancias de otra entidad.
- Muchos a uno (N:1): Varias instancias de una entidad están relacionadas con una única instancia de otra entidad.
- Muchos a muchos (N:N): Varias instancias de una entidad pueden estar relacionadas con varias instancias de otra entidad.
2. Clave primaria y clave foránea:
Para establecer una relación entre dos entidades, es necesario utilizar las claves primarias y las claves foráneas. La clave primaria es un atributo único dentro de una entidad que permite identificar de manera unívoca cada instancia. La clave foránea es un atributo que hace referencia a la clave primaria de otra entidad, estableciendo así la relación entre ellas.
3. Tipos de integridad referencial:
Al establecer relaciones entre entidades en una base de datos, es importante garantizar la integridad referencial. Los principales tipos de integridad referencial son:
- Restricción DELETE: Define qué sucede con los registros de una entidad relacionada cuando se elimina un registro en la entidad principal.
- Restricción UPDATE: Define qué sucede con los registros de una entidad relacionada cuando se modifica un registro en la entidad principal.
- Restricción INSERT: Define qué sucede con los registros de una entidad relacionada cuando se inserta un nuevo registro en la entidad principal.
4. Normalización de relaciones:
La normalización es el proceso de organizar las tablas y las relaciones en una base de datos para eliminar la redundancia y mejorar la eficiencia. Existen diferentes formas normales, como la primera forma normal (1NF), segunda forma normal (2NF) y tercera forma normal (3NF), cada una con reglas específicas que deben cumplirse para asegurar una estructura de base de datos óptima.
5. Consultas JOIN:
Las consultas JOIN son utilizadas para combinar datos de múltiples tablas basándose en condiciones relacionales. Las principales consultas JOIN son:
- INNER JOIN: Retorna solamente las filas que tienen coincidencias en ambas tablas involucradas.
- LEFT JOIN: Retorna todas las filas de la tabla izquierda y las coincidentes de la tabla derecha.
- RIGHT JOIN: Retorna todas las filas de la tabla derecha y las coincidentes de la tabla izquierda.
- FULL OUTER JOIN: Retorna todas las filas de ambas tablas, incluyendo las no coincidentes.
Una relación en una base de datos es una conexión lógica entre dos tablas que permite establecer vínculos y realizar consultas relacionadas.
En una relación uno a uno, un registro en una tabla solo puede estar vinculado a un registro en otra tabla, mientras que en una relación uno a muchos, un registro en una tabla puede estar vinculado a varios registros en otra tabla.
Una relación en una base de datos relacional se representa mediante una clave foránea, que es un campo en una tabla que hace referencia al campo clave primaria de otra tabla.
La integridad referencial es una regla que garantiza que los vínculos entre las tablas en una base de datos son válidos y consistentes, evitando la existencia de registros huérfanos o referencias incorrectas.
No, si un registro tiene vínculos con otras tablas mediante una clave foránea, no se puede eliminar directamente el registro. Antes de eliminarlo, se deben eliminar o actualizar los registros relacionados en las otras tablas para mantener la integridad referencial.
Entradas relacionadas
Deja una respuesta
Entradas relacionadas